Building AI Tools You Can Trust
Published on November 16, 2025. · 13 min read
You want to build an AI application. Something useful. Something your users can rely on.
But here’s the problem: How do you know it’s actually good?
You can build an app that generates summaries, answers questions, or writes emails. It works. Your tests pass. But is it reliable? Does it hallucinate? Does it miss important information? Is it actually trustworthy?
The philosophy is simple:
You can’t improve what you don’t measure.
Let me paint a realistic scenario:
You’ve built a summarization app. Users love the interface. The summaries look great. But then:
-
A news outlet tries your app and finds the summary omits a crucial financial number
-
A researcher uses it and discovers the summary makes a claim that’s not in the original paper
-
A student uses it and the summary misrepresents the nuance of the source material
Sound familiar? This happens all the time in full-stack AI apps because people build features without measuring quality.
The difference between a hobby project and a professional tool is this: Professional tools measure themselves.
Our Journey: Building a Trustworthy Summarization Tool
Let’s start 🚀
If you want to follow along, here the repo. There’s also a notebook which has everything I’ll be covering in this article.
Run in Google Colab
No installation. No setup. Just click and start:
![]()
Quick start:
-
Click the button above
-
Run the first cell (installs dependencies)
-
Add your OpenAI API key to Colab Secrets (click 🔑 icon)
-
Run the remaining cells
-
See your evaluation scores
-
Experiment with optimization strategies
🏠 Run Locally
Then follow the cells to:
-
Generate summaries
-
Run evaluations
-
Compare strategies
-
Understand your metrics
Step 1: Setting Up
First, install the dependencies:
pip install ragas==0.3.9 langchain-openai langchain-core python-dotenvThese packages give us:
-
ragas - The evaluation framework
-
langchain-openai - Access to GPT models
-
python-dotenv - Manage API keys safely
Now let’s initialize everything:
import os
import asyncio
from typing import Optional
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
api_key = os.environ.get("OPENAI_API_KEY")
llm_model = os.environ.get("LLM_MODEL", "gpt-4o-mini")
# Initialize OpenAI client
from openai import AsyncOpenAI
client = AsyncOpenAI(api_key=api_key)
# Setup RAGAS for evaluation
from ragas.llms import llm_factory
from ragas.metrics.collections import SummaryScore, Faithfulness
llm = llm_factory(llm_model, client=client)
print("✅ Setup complete!")Step 2: Load an Article
Let’s load some content to summarize:
article = """
Apple announced on Tuesday that it will invest $1 billion in new AI research centers
across the United States over the next five years. The company plans to hire 500 new
researchers and engineers specifically for AI development. CEO Tim Cook stated that
artificial intelligence is central to the company's future product strategy. The investment
will focus on areas like natural language processing, computer vision, and machine learning
efficiency. Apple will establish research hubs in San Francisco, Boston, and Seattle.
The company already employs over 10,000 AI researchers globally.
"""
print(f"📰 Article: {len(article.split())} words")Step 3: Generate a Summary
Now let’s actually summarize it using an LLM:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
# Initialize the summarizer
summarizer = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.3)
# Create a prompt
summarization_prompt = PromptTemplate(
input_variables=["text"],
template="""Summarize the following text in 2-3 sentences.
Focus on the main points and key details.
Text:
{text}
Summary:"""
)
# Generate the summary
chain = summarization_prompt | summarizer
response = chain.invoke({"text": article})
generated_summary = response.content.strip()
print("✍️ Generated Summary:")
print(generated_summary)This gives us something like:
“Apple is investing $1 billion in AI research over five years, planning to hire 500 researchers across three US cities. The investment focuses on natural language processing, computer vision, and machine learning efficiency.”
Looks good, right? But is it actually good? That’s the question.
This is where things get interesting.
Instead of relying on intuition, we’re going to measure the summary using objective metrics.
Understanding Metric #1: Summary Score
What it measures: Does your summary capture the important information from the source?
How it works:
-
RAGAS extracts key phrases from the original article
-
It generates questions about those key phrases
-
It checks if your summary answers those questions
-
The score is the percentage of questions answered correctly
Why this matters: You could have a summary that sounds good but actually misses critical details. If the original article mentions “$1 billion” and your summary skips it, the Summary Score will reflect that loss.
What the scores mean:
-
0.8-1.0 ✅ Excellent - You’ve captured essential information
-
0.6-0.8 ✅ Good - Main points are present
-
0.4-0.6 ⚠️ Fair - Missing important details
-
<0.4 ❌ Poor - Significant information loss
Example:
Understanding Metric #2: Faithfulness
What it measures: Is your summary making stuff up? Is it hallucinating?
How it works:
-
RAGAS breaks down the summary into individual claims
-
For each claim, it checks: “Is this claim supported by the source?”
-
It flags claims that don’t appear in the original text
-
The score is the percentage of claims that are grounded in the source
Why this matters: A hallucinated fact is worse than a missing fact. If your summary invents information, you’re not just losing accuracy, you’re actively spreading misinformation.
What the scores mean:
-
0.9-1.0 ✅ Excellent - Fully grounded, no hallucinations
-
0.7-0.9 ✅ Good - Mostly accurate
-
0.5-0.7 ⚠️ Fair - Some ungrounded claims
-
<0.5 ❌ Poor - Contains hallucinations
Example:
Choosing Your Metrics: Not All Use Cases Are the Same
Different applications need different priorities:
| Use Case | Summary Score | Faithfulness | Why? |
|---|---|---|---|
| News articles | 30% weight | 70% weight | Accuracy is everything. Missing a detail is okay if what’s there is true. |
| Research papers | 70% weight | 30% weight | Completeness matters. You need the findings. Hallucination is bad but rarer in structured text. |
| Financial reports | 40% weight | 60% weight | One false number can cost millions. Accuracy > completeness. |
| Learning materials | 50% weight | 50% weight | Students need both complete AND accurate summaries. |
| Social media | 80% weight | 20% weight | Engagement and quick takeaway. Perfection isn’t necessary. |
The key: Decide your priorities before you build.
Now let’s actually measure our summary:
# Initialize the evaluation metrics
summary_score_metric = SummaryScore(llm=llm)
faithfulness_metric = Faithfulness(llm=llm)
async def evaluate_summary():
"""Evaluate the summary I just created"""
print("🔍 Evaluating summary...\n")
try:
# Metric 1: Summary Score
print("⏳ Computing Summary Score...")
summary_result = await summary_score_metric.ascore(
reference_contexts=[article], # The original article
response=generated_summary # Our summary
)
summary_score = float(summary_result.value)
print(f" ✅ Summary Score: {summary_score:.3f}")
print(f" Captures {summary_score*100:.0f}% of key information\n")
# Metric 2: Faithfulness
print("⏳ Computing Faithfulness...")
faithfulness_result = await faithfulness_metric.ascore(
user_input=article,
response=generated_summary,
retrieved_contexts=[article]
)
faithfulness = float(faithfulness_result.value)
print(f" ✅ Faithfulness: {faithfulness:.3f}")
print(f" {faithfulness*100:.0f}% of claims are grounded in source\n")
return {
"summary_score": summary_score,
"faithfulness": faithfulness,
}
except Exception as e:
print(f"❌ Error: {e}")
return None
# Run the evaluation
results = await evaluate_summary()Here’s what just happened:
-
You sent your summary to an LLM evaluator
-
The evaluator analyzed it against the original article
-
You got objective scores that tell you exactly how good your summary is
-
You now have data instead of vibes
This is the difference between guessing and knowing.
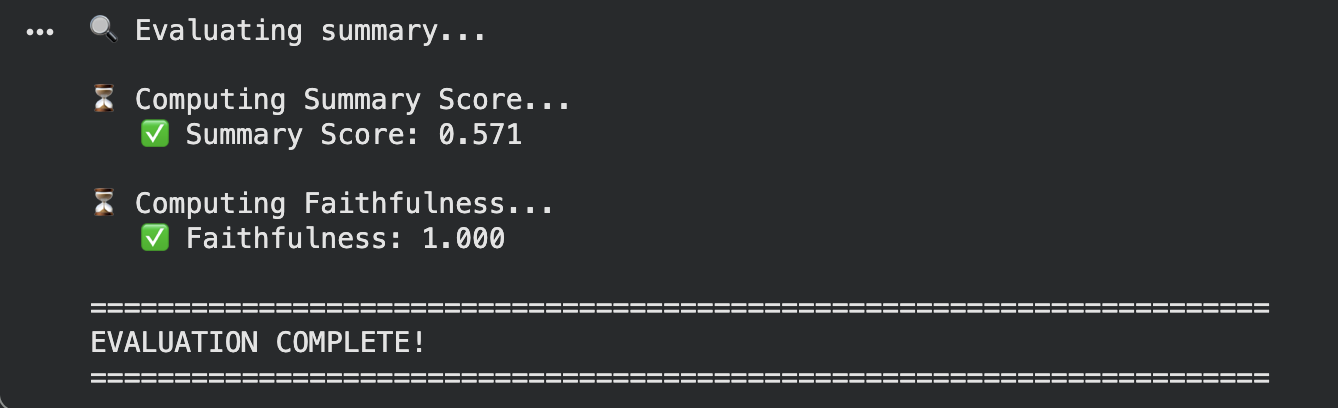
Here, we got a good score on faithfulness. However summary score says it’s got lots of room for improvement.
The beauty of having metrics is that you can test different approaches and see which works best:
Strategy 1: Longer Summaries
Maybe 2-3 sentences isn’t enough. Let’s try 5-7:
longer_prompt = PromptTemplate(
input_variables=["text"],
template="""Summarize the following text in 5-7 sentences.
Capture all key points, numbers, and important details.
Text:
{text}
Summary:"""
)
chain = longer_prompt | summarizer
longer_summary = chain.invoke({"text": article}).content.strip()Trade-off: Longer summaries usually score higher on Summary Score (more information), but you lose compression and some readers might not read it all.
Strategy 2: Structured Prompt
Guide the LLM to focus on specific aspects:
structured_prompt = PromptTemplate(
input_variables=["text"],
template="""Summarize focusing on:
- WHAT (the action/announcement)
- WHY (the reason/motivation)
- WHERE (locations involved)
- HOW MUCH (numbers and scale)
- WHO (the organization)
Text:
{text}
Summary:"""
)
chain = structured_prompt | summarizer
structured_summary = chain.invoke({"text": article}).content.strip()Why it works: By explicitly asking for key details, the LLM is less likely to skip them.
Strategy 3: Bullet Points
Sometimes format matters:
bullet_prompt = PromptTemplate(
input_variables=["text"],
template="""Summarize as 4-5 bullet points.
Each bullet should state ONE key fact.
Text:
{text}
Summary:"""
)
chain = bullet_prompt | summarizer
bullet_summary = chain.invoke({"text": article}).content.strip()Evaluate all three and see which one wins:
async def compare_strategies():
"""Compare different summarization approaches"""
strategies = {
'longer': longer_summary,
'structured': structured_summary,
'bullets': bullet_summary
}
print("Testing different strategies...\n")
results = {}
for name, summary in strategies.items():
print(f"Evaluating: {name}")
score = await summary_score_metric.ascore(
reference_contexts=[article],
response=summary
)
faith = await faithfulness_metric.ascore(
user_input=article,
response=summary,
retrieved_contexts=[article]
)
results[name] = {
'summary_score': float(score.value),
'faithfulness': float(faith.value),
'combined': float(score.value) + float(faith.value)
}
print(f" Summary Score: {results[name]['summary_score']:.3f}")
print(f" Faithfulness: {results[name]['faithfulness']:.3f}")
print(f" Combined: {results[name]['combined']:.3f}\n")
# Find the winner
best = max(results.items(), key=lambda x: x[1]['combined'])
print(f"🏆 Winner: {best[0].upper()}")
print(f" Combined Score: {best[1]['combined']:.3f}")
return results
# Run it
comparison_results = await compare_strategies()This is empirical optimization. You’re not guessing which approach is best, you’re measuring and letting data decide.
Here’s what we’ve built so far:
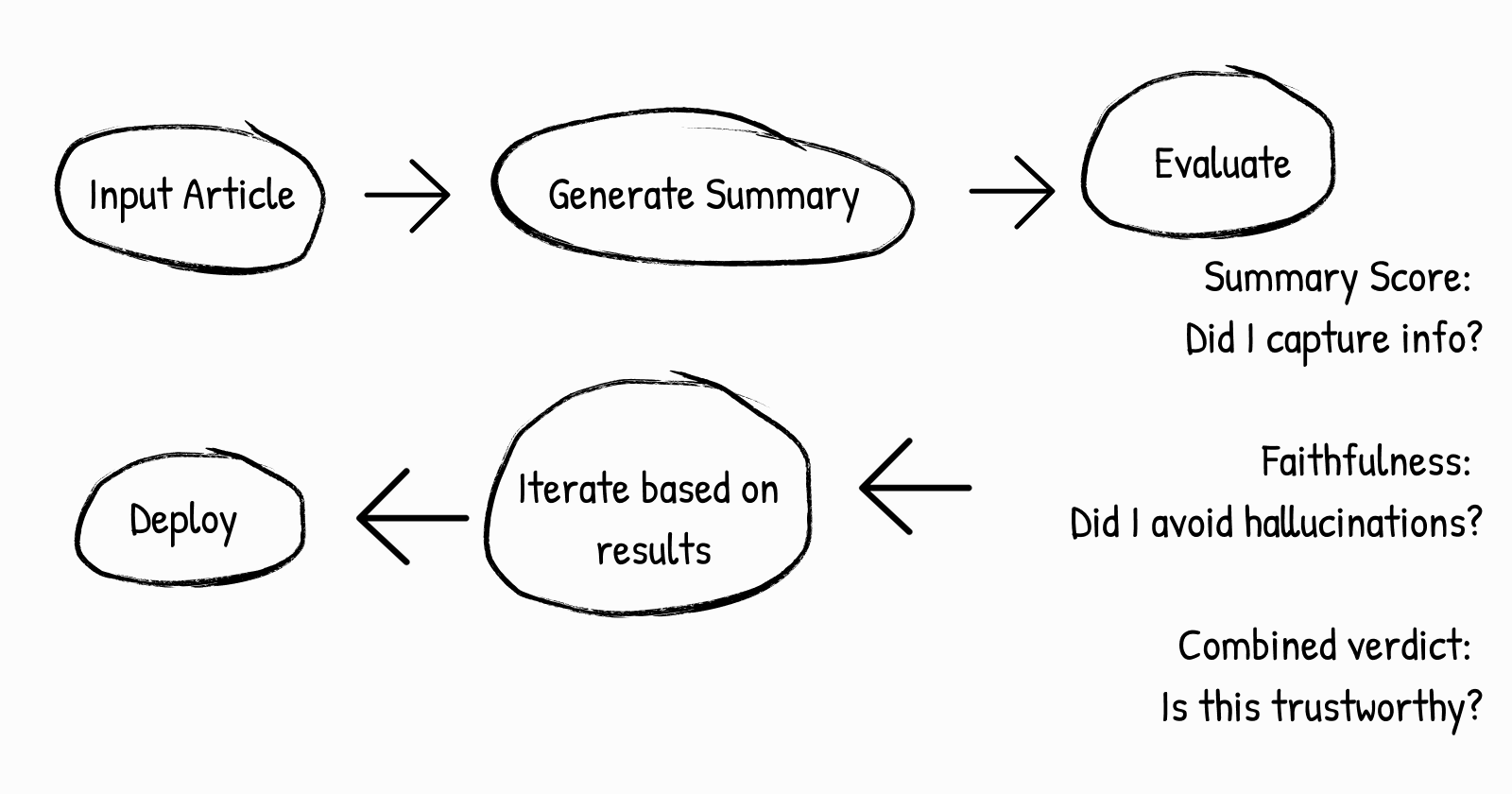
This workflow is powerful because:
-
Objective feedback - No subjective opinions, just scores
-
Continuous improvement - You can always test new approaches
-
Quality gates - You can set minimum scores before publishing
-
Learning loop - Over time, you understand what works for your use case
Now that you understand how evaluation works, here are practical guidelines for building production systems:
✅ DO’s
1. DO Set Minimum Score Thresholds
Define what “good enough” means before you deploy:
SUMMARY_SCORE_THRESHOLD = 0.75
FAITHFULNESS_THRESHOLD = 0.90
def is_summary_publishable(results):
return (results['summary_score'] >= SUMMARY_SCORE_THRESHOLD and
results['faithfulness'] >= FAITHFULNESS_THRESHOLD)
if is_summary_publishable(results):
publish_summary()
else:
flag_for_manual_review()Different use cases need different thresholds:
-
News outlets: 0.85+ (accuracy critical)
-
Research papers: 0.80+ (completeness critical)
-
Social media: 0.60+ (engagement over perfection)
-
Learning platforms: 0.75+ (balance needed)
2. DO Test Multiple Models
Different models produce different quality:
models = ["gpt-3.5-turbo", "gpt-4o-mini", "gpt-4"]
for model in models:
summarizer = ChatOpenAI(model=model)
summary = generate_summary(article, summarizer)
score = evaluate_summary(summary)
print(f"{model}: {score:.3f}")
# Pick the best performerGPT-3.5 is cheap. GPT-4 is better. GPT-4o-mini is the sweet spot for many use cases. Let metrics decide.
3. DO Monitor Evaluation Costs
Evaluations cost money. Budget accordingly:
# Track costs
EVAL_COST_PER_SUMMARY = 0.004 # Rough estimate
# Sample evaluation, don't evaluate everything
sample_size = min(100, len(all_summaries)) # Sample 100 or all
eval_cost = sample_size * EVAL_COST_PER_SUMMARY
print(f"Evaluating {sample_size} summaries will cost: ${eval_cost:.2f}")For production: sample 10% of summaries. For critical content: evaluate 100%. For bulk operations: sample even less.
4. DO Create a Feedback Loop
Use metrics to continuously improve:
# Log everything
import json
from datetime import datetime
log_entry = {
"timestamp": datetime.now().isoformat(),
"article_length": len(article.split()),
"model": "gpt-3.5-turbo",
"summary_score": 0.82,
"faithfulness": 0.93,
"strategy": "structured_prompt"
}
with open("evaluation_log.jsonl", "a") as f:
f.write(json.dumps(log_entry) + "\n")
# Later: analyze patterns
# - Which prompts work best?
# - Do long articles score lower?
# - Is there seasonality?5. DO Test With Real Data
Example articles are for learning. Test with your actual content:
# Load your real articles
from pathlib import Path
your_articles = []
for file in Path("/path/to/articles").glob("*.txt"):
with open(file) as f:
your_articles.append(f.read())
# Evaluate on real data
for article in your_articles:
summary = generate_summary(article)
results = evaluate_summary(summary)
# Analyze real-world performance
avg_score = sum(r['summary_score'] for r in results) / len(results)6. DO Document Your Decisions
Future you will thank present you:
"""
Summarization System Configuration
===================================
Created: 2025-01-15
Purpose: Production summarization service
Decisions:
- Model: gpt-4o-mini (cost/quality balance)
- Summary Length: 3-5 sentences
- Minimum Thresholds:
* Summary Score: 0.75
* Faithfulness: 0.85
- Rejection Strategy: Flag for manual review
Trade-offs:
- Not using GPT-4 to save costs
- Accepting 78% info preservation for speed
- Manual review for edge cases
Review Date: 2025-02-15
"""7. DO Handle Errors Gracefully
APIs fail. Networks go down. Budget runs out:
try:
score = await summary_metric.ascore(...)
except RateLimitError:
logger.warning("Rate limited, retrying...")
await asyncio.sleep(60)
score = await summary_metric.ascore(...)
except APIError as e:
logger.error(f"API error: {e}")
flag_for_manual_review(summary)
score = None❌ DON’Ts
1. DON’T Trust Metrics Blindly
Metrics are tools, not oracles. Always have humans review:
# BAD: Automate based purely on score
if summary_score > 0.8:
publish_summary() # ❌ Wrong!
# GOOD: Use metrics as a guide
if summary_score > 0.8:
send_to_human_review() # Human has final say2. DON’T Ignore Faithfulness for Speed
Don’t optimize only for Summary Score at the expense of Faithfulness:
# BAD: Chasing higher Summary Score by any means
prompt = "Include EVERY DETAIL from the article" # ❌
# Result: Longer summaries, higher Summary Score, but hallucinations
# GOOD: Balance both
prompt = "Summarize accurately without adding new information"Hallucinations destroy trust. One false claim tanks your credibility.
3. DON’T Hardcode API Keys
Never, ever, ever:
# TERRIBLE
api_key = "sk-proj-abc123xyz..." # ❌❌❌
# GOOD
load_dotenv()
api_key = os.environ.get("OPENAI_API_KEY")Add .env to .gitignore. Make this a habit.
4. DON’T Evaluate Everything
Evaluations cost money. Be strategic:
# BAD: Evaluate all 10,000 summaries ($40+)
for summary in all_summaries:
evaluate_summary(summary) # ❌ Expensive
# GOOD: Statistical sampling
sample = random.sample(all_summaries, k=100) # 1% sample
for summary in sample:
evaluate_summary(summary) # ✅ Cheap, representative5. DON’T Use Metrics As Your Only Quality Gate
Metrics are one dimension. Add more layers:
# BAD: Only checking metrics
if summary_score > 0.8:
publish_summary() # ❌
# GOOD: Multiple checks
quality_checks = {
"metrics": evaluate_summary(summary), # Objective
"human_review": manual_review(summary), # Subjective
"guidelines": check_brand_guidelines(summary), # Policy
"safety": toxicity_check(summary) # Safety
}
if all(c.passed for c in quality_checks.values()):
publish_summary() # ✅6. DON’T Use the Same Model for Summarization and Evaluation
It’s like asking a student to grade their own homework:
# AVOID: Self-grading bias
summarizer = ChatOpenAI(model="gpt-3.5-turbo")
evaluator = ChatOpenAI(model="gpt-3.5-turbo") # Bias!
# BETTER: Different models
summarizer = ChatOpenAI(model="gpt-3.5-turbo") # Fast, cheap
evaluator = ChatOpenAI(model="gpt-4") # Rigorous7. DON’T Assume One Evaluation Equals Truth
LLM evaluations have variance. Run multiple times for important decisions:
# BAD: Single evaluation
score = await summary_metric.ascore(...)
if score < 0.7:
reject_summary() # ❌ What if this was an anomaly?
# GOOD: Multiple runs
scores = []
for _ in range(3):
score = await summary_metric.ascore(...)
scores.append(float(score.value))
avg_score = sum(scores) / len(scores)
if avg_score < 0.7:
reject_summary() # ✅ More reliableCommon Pitfalls & How to Avoid Them
Pitfall #1: The Score Plateau
Your Summary Score hits 0.75 and won’t improve.
Why: You’ve hit the architectural limits of your approach.
Solution:
-
Try a completely different prompt (not tweaks, but fundamentally different)
-
Switch to a more capable model (GPT-4 instead of 3.5)
-
Increase summary length (allows more information)
Pitfall #2: The Faithfulness Trap
Faithfulness is 0.95 but users say summaries are useless.
Why: You’re being so cautious you lose nuance. Or metrics don’t match user expectations.
Solution:
-
Add human feedback alongside metrics
-
Verify that metrics actually align with user satisfaction
-
Faithfulness ≠ usefulness
Pitfall #3: Runaway Costs
Your evaluation budget exploded unexpectedly.
Why: Evaluated too much, used expensive models, pricing changed.
Solution:
BUDGET = 100 # $100/month
COST_PER_EVAL = 0.004
MAX_EVALS = int(BUDGET / COST_PER_EVAL) # 25,000
eval_count = 0
for summary in summaries:
if eval_count >= MAX_EVALS:
logger.warning("Budget limit reached")
break
evaluate_summary(summary)
eval_count += 1Pitfall #4: Model Drift
Your system worked for 3 months, then scores dropped mysteriously.
Why: OpenAI updated their model, or your data changed.
Solution:
# Set a baseline
baseline = {
"date": "2025-01-15",
"model": "gpt-4o-mini",
"avg_score": 0.78
}
# Monthly check-in
current = evaluate_sample()
if current["avg_score"] < baseline["avg_score"] * 0.95:
alert("Score degradation detected!")Learn More
Want to dive deeper?
-
RAGAS Documentation - Official docs with all metrics explained
-
Summary Score Details - How Summary Score works under the hood
-
Faithfulness Metric - Deep dive into hallucination detection
-
LangChain Documentation - Building LLM applications
-
Prompt Engineering Best Practices - OpenAI’s guide to writing better prompts
You can also use more latest gpt-5 series of course or other providers like claude, gemini, etc.
Building AI applications is easy. Building trustworthy AI applications is harder, but not impossibly so.
The difference is measurement. Metrics. Data.
Every time someone asks you, “How do you know your AI summaries are accurate?” you can now answer confidently:
“Because I measure it. Every single time. With objective metrics. And I continuously optimize based on those measurements.”
That’s what separates hobby projects from professional tools.
You now have everything you need to build AI you can trust.
Questions? Found a bug? Have ideas?
Open an issue on GitHub and let’s build better AI together.
Happy building! 🚀