Teaching AI to Grade Other AI
Published on November 9, 2025. · 10 min read
If you’ve been following the world of AI development, you might’ve heard the phrase “LLM-as-Judge.”
It sounds dramatic, like some sci-fi overlord where one AI passes judgment on another. But it’s actually one of the most important evolutions in evaluating large language models (LLMs).
LLM-as-Judge means using a language model itself to evaluate the quality of another model’s responses.
Traditionally, human annotators graded model outputs. Checking if an answer was factual, polite, relevant, or well-reasoned. But as models got more capable and outputs more nuanced, this manual process became slow, expensive, and inconsistent.
So, researchers began asking, Can we train (or prompt) a model to act like a human evaluator?
Turns out, yes, quite effectively.
The idea is simple:
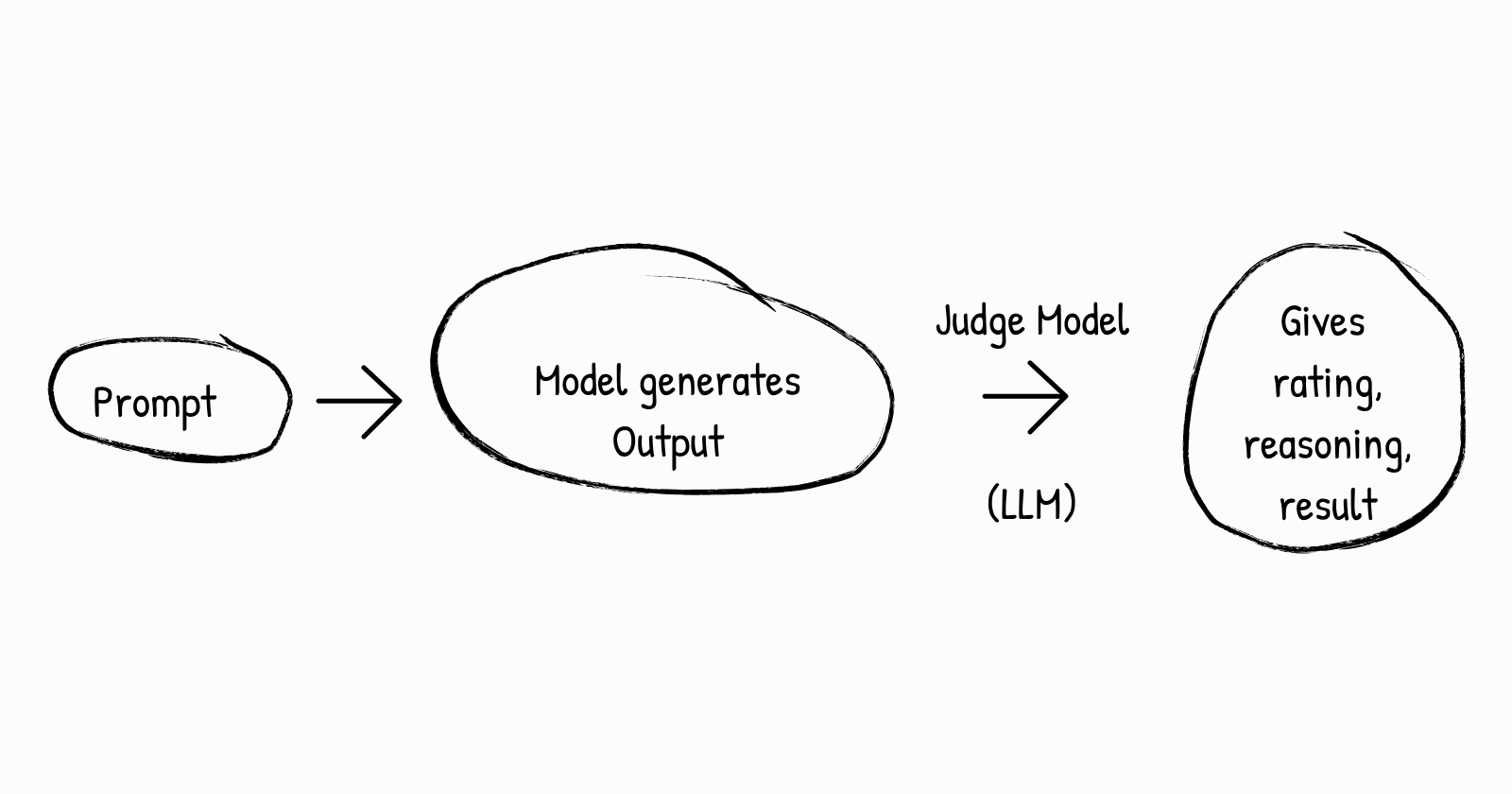
It’s like using one AI to peer-review another. Evaluation is the backbone of AI progress. Without it, we wouldn’t know if newer models are actually better, or just different. Human evaluation doesn’t scale. Imagine evaluating thousands of answers for correctness, reasoning, and tone across 10+ benchmarks.
That’s days of work for humans, but minutes for an LLM.
You now suddenly have the super power to run thousands of comparisons in minutes. Reduce human bias, enable rapid iteration and explore subjective criteria like “creativity” or “helpfulness” where metrics alone fall short.
LLM-based judging has already become a norm in multiple domains:
| Use Case | Description |
|---|---|
| Model benchmarking | Frameworks like Arena Hard and MT-Bench use GPT-4 as the judge to rank models. |
| Eval pipelines | Tools like Ragas and TruLens integrate LLM-judging to score faithfulness, coherence, and relevance. |
| Fine-tuning and alignment | Reinforcement Learning from AI Feedback (RLAIF) replaces human feedback with LLM judgments to train new models. |
| Automated grading systems | Education and coding platforms use LLMs to grade free-text answers or code explanations. |
LLM-as-Judge solves for critical limitations with traditional evaluation metrics:
-
Captures nuance: Evaluates semantic quality, not just string overlap
-
Scales human judgment: Automates what would otherwise require manual review
-
Flexible criteria: Define any custom evaluation criteria
-
Domain-aware: Adapts to specific use cases (medical, legal, finance, etc.)
-
Interpretable: Provides reasoning for verdicts, not just scores
Without scalable evaluation, progress slows down. Model quality becomes subjective. Everyone claims their model is “better,” but without consistent evals, it’s marketing, not science. Human fatigue and cost make it impossible to iterate fast. Bias creeps in. Different annotators interpret “good” differently. An LLM judge can apply consistent criteria across thousands of examples.
In short, without a judge, the AI ecosystem risks flying blind.
Think of the evaluation as a comparison pipeline:
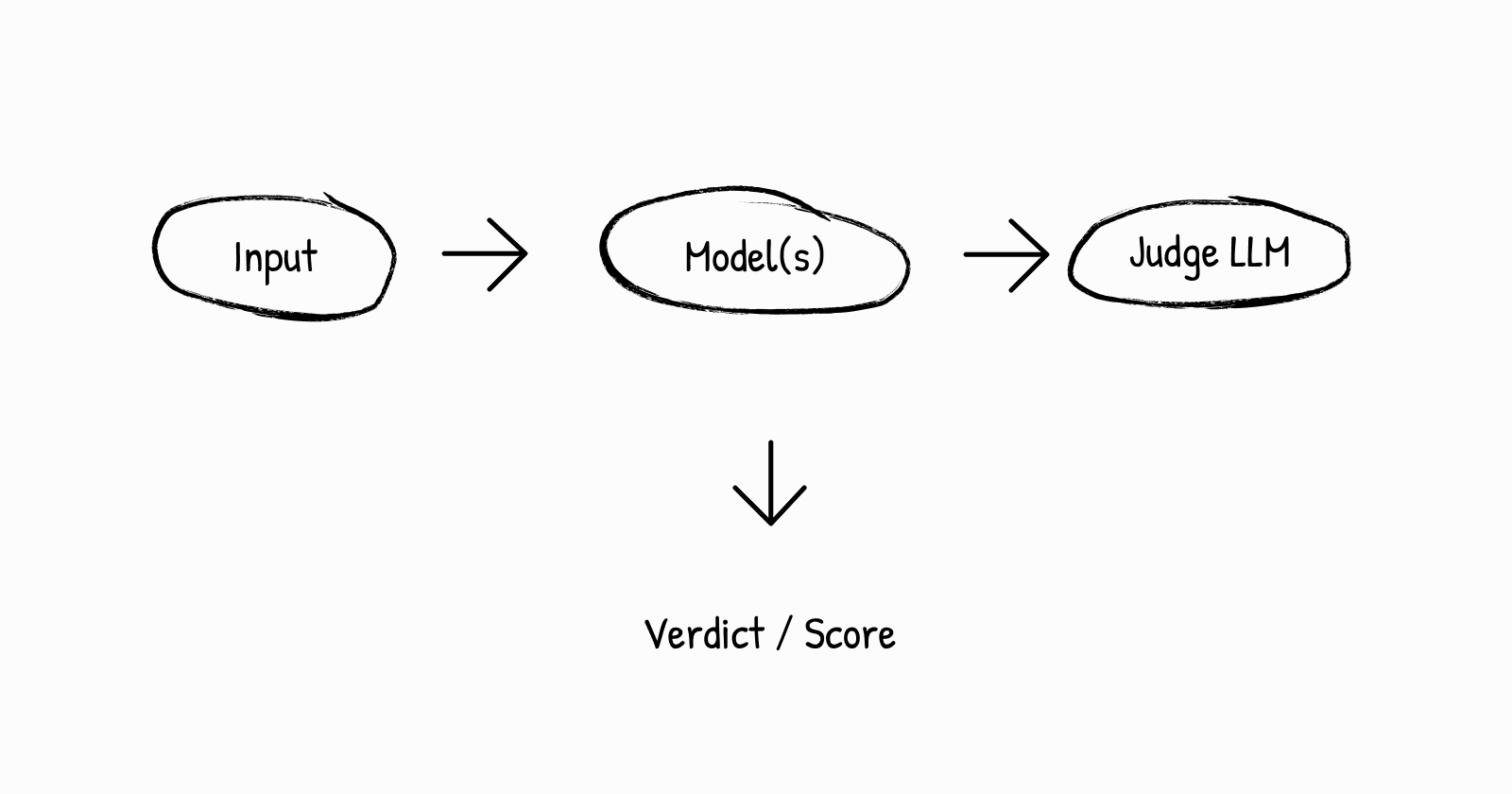
Before your LLM judge can reliably evaluate your system, it must first align with your ground truth (human expert judgments). A misaligned judge is like a compass pointing the wrong way—every improvement based on its guidance moves you further from your goal. Ragas provides a powerful, production-ready framework for implementing LLM-as-Judge evaluation.
Let’s talk about the alignment process. First, you start by creating a baseline judge using a straightforward prompt. Then, you evaluate it against human-labeled ground truth to see how it measures up. Next, you look for patterns where the judge disagrees with the human experts. Based on these patterns, you tweak and improve the judge’s prompt. After that, you re-evaluate to see if there’s any improvement. You keep repeating this process until the alignment either levels off or reaches the standard you’re aiming for.
The strictness parameter controls consistency by running multiple evaluations with majority voting:
-
Value: Number of independent LLM evaluations
-
Mechanism: Majority voting combines results
-
Auto-adjustment: Automatically converts to odd numbers (1, 3, 5, 7…)
Use 2-4 for production, balancing cost and consistency.
Think of DiscreteMetric as the Swiss Army knife of LLM-based evaluation. Need to evaluate responses as “excellent,” “good,” “mediocre,” or “poor”? DiscreteMetric handles it. Want to categorize code reviews as “passes linting,” “needs minor fixes,” or “major refactoring required”? You’ve got it. The key insight is that DiscreteMetric lets you define both the evaluation prompt AND the allowed output values, making it incredibly flexible for nuanced evaluations that don’t fit neatly into binary or numeric scoring.
What makes DiscreteMetric particularly powerful is that you don’t need to subclass anything or write complex metric implementations. You just provide a prompt template (with variables you define), specify what categorical values the LLM can return, and you’re done. The LLM does the actual evaluation work using your custom prompt, and returns one of your predefined categories. This is perfect for domain-specific evaluation criteria where you need more granularity than binary but want to avoid the complexity of numeric scores.
For example, if you’re evaluating financial advice, you might want categories like “financially sound,” “incomplete,” “contains risk,” or “dangerous advice” — each with different implications for your system. Or for content moderation, you might use “safe,” “borderline,” “needs review,” and “block.” DiscreteMetric adapts to whatever categorical scheme your business needs.
import asyncio
from openai import AsyncOpenAI
from ragas.llms import llm_factory
from ragas.metrics import DiscreteMetric
import os
async def main():
# Setup
client = AsyncOpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
llm = llm_factory("gpt-4o-mini", client=client)
# Define metric
accuracy_metric = DiscreteMetric(
name="accuracy",
prompt="Check if the response contains points from the grading
notes.\n\nResponse: {response}\nGrading Notes: {grading_notes}",
allowed_values=["pass", "fail"],
llm=llm
)
# Evaluate
result = await accuracy_metric.ascore(
response="The model discussion covers DCF, comparable analysis, and VC
methods",
grading_notes="Must cover: DCF method, comparable analysis, VC method,
founder impact"
)
print(f"Verdict: {result.value}") # "pass" or "fail"
print(f"Reason: {result.reason}")
# Run
asyncio.run(main())Now that we understand DiscreteMetric, let’s build a complete judge evaluation pipeline from scratch.
Define Your Evaluation Criteria
Start by clearly defining what “good” means for your use case.
# Example: Evaluating financial advice quality
judge_definition = """
Evaluate if the response provides sound financial advice that covers:
1. Clear explanation of key concepts
2. Relevant metrics and calculations
3. Risk considerations
4. Tax implications where applicable
5. Practical actionable steps
Return 'pass' if all major points are covered, 'fail' if critical topics are missing.
"""Create a Baseline Judge
Start with a simple baseline judge helps you understand the problem.
from ragas.metrics import DiscreteMetric
from openai import AsyncOpenAI
from ragas.llms import llm_factory
# Initialize LLM
client = AsyncOpenAI(api_key="sk-...")
llm = llm_factory("gpt-4o-mini", client=client)
# Create baseline judge
baseline_judge = DiscreteMetric(
name="financial_advice_quality",
prompt="Does the response provide sound financial advice? Check for key concepts, calculations, risks, and actionable steps.\n\nResponse: {response}",
allowed_values=["pass", "fail"]
)Prepare Ground Truth Data
You need human-labeled examples to measure alignment.
import pandas as pd
from ragas import Dataset
# Load your annotated data
df = pd.read_csv("expert_labels.csv")
# Expected columns: question, response, expert_judgment
dataset = Dataset(name="judge_alignment", backend="local/csv")
for _, row in df.iterrows():
dataset.append({
"question": row["question"],
"response": row["response"],
"target": row["expert_judgment"]
})Create Alignment Metric
Define how you measure judge alignment.
from ragas.metrics.discrete import discrete_metric
from ragas.metrics.result import MetricResult
@discrete_metric(name="judge_alignment", allowed_values=["pass", "fail"])
def judge_alignment(judge_label: str, human_label: str) -> MetricResult:
"""Compare judge decision with human label."""
judge = judge_label.strip().lower()
human = human_label.strip().lower()
if judge == human:
return MetricResult(
value="pass",
reason=f"Judge={judge}; Human={human}"
)
return MetricResult(
value="fail",
reason=f"Judge={judge}; Human={human}"
)Define Experiment Function
Orchestrate the evaluation pipeline.
from ragas import experiment
from typing import Dict, Any
@experiment()
async def judge_experiment(
row: Dict[str, Any],
judge_metric: DiscreteMetric,
llm,
):
"""Run complete evaluation: Judge → Compare with human."""
judge_score = await judge_metric.ascore(
question=row["question"],
response=row["response"],
llm=llm
)
alignment = judge_alignment.score(
judge_label=judge_score.value,
human_label=row["target"]
)
return {
**row,
"judge_label": judge_score.value,
"judge_reason": judge_score.reason,
"alignment": alignment.value
}Run Baseline Evaluation
Execute the evaluation pipeline.
import asyncio
import os
async def run_baseline():
# Load dataset
dataset = load_dataset()
print(f"Loaded {len(dataset)} samples")
# Initialize LLM
client = AsyncOpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
llm = llm_factory("gpt-4o-mini", client=client)
# Run experiment
results = await judge_experiment.arun(
dataset,
name="judge_baseline_v1",
judge_metric=baseline_judge,
llm=llm
)
# Calculate alignment
passed = sum(1 for r in results if r["alignment"] == "pass")
total = len(results)
print(f"Alignment: {passed}/{total} ({passed/total:.1%})")
return results
# Execute
results = asyncio.run(run_baseline())Analyze Errors
Identify patterns in judge errors.
import pandas as pd
# Load results
df = pd.read_csv("judge_baseline_v1.csv")
# Analyze misalignments
false_positives = len(df[
(df['judge_label'] == 'pass') & (df['target'] == 'fail')
])
false_negatives = len(df[
(df['judge_label'] == 'fail') & (df['target'] == 'pass')
])
print(f"False positives (too lenient): {false_positives}")
print(f"False negatives (too strict): {false_negatives}")
# Look at specific error examples
errors = df[df['alignment'] == 'fail']
for idx, row in errors.head(5).iterrows():
print(f"\nQuestion: {row['question']}")
print(f"Judge: {row['judge_label']}, Human: {row['target']}")
print(f"Reason: {row['judge_reason']}")Improve Judge Prompt
Based on error patterns, create an improved judge.
# Improved prompt addressing identified issues
improved_judge = DiscreteMetric(
name="financial_advice_quality_v2",
prompt="""Evaluate if the response provides comprehensive financial advice.
CRITERIA:
1. ✓ Must clearly explain key financial concepts
2. ✓ Must include relevant calculations or metrics
3. ✓ Must discuss risks and tax implications
4. ✓ Must provide actionable next steps
5. ✓ Must avoid generic advice without specifics
IMPORTANT:
- Require ALL 5 criteria to be present
- Do NOT accept vague or general statements
- Accept paraphrased concepts (different wording is OK)
- If even one criterion is missing or vague, return 'fail'
Response: {response}
Are all 5 criteria clearly met in the response? Answer 'pass' or 'fail'.""",
allowed_values=["pass", "fail"]
)Re-run with Improved Judge
Execute with the improved version.
async def run_improved():
dataset = load_dataset()
client = AsyncOpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
llm = llm_factory("gpt-4o-mini", client=client)
# Use improved judge
results = await judge_experiment.arun(
dataset,
name="judge_improved_v2",
judge_metric=improved_judge,
llm=llm
)
passed = sum(1 for r in results if r["alignment"] == "pass")
total = len(results)
print(f"Improved alignment: {passed}/{total} ({passed/total:.1%})")
return results
results = asyncio.run(run_improved())It’s of course not a simple single step process. You gotta at least do it a few times. Keep iterating till you find that sweet spot.
You can also run multiple judges and combine results, evaluate the entire conversation flow or create your metric implementation. I’ll leave that to you to figure out. A super tip that helped me learn faster was to include examples in prompts to improve judge accuracy. Make it as verbose as you can. Avoid jargons or explain any jargons that you’re using. For example, LLM might not know what ARR means.
Best Practices
-
Start with Domain Experts - Ground truth quality is critical
-
Document Evaluation Criteria - Clear criteria prevents ambiguity
-
Measure Inter-Rater Reliability - Use multiple annotators to validate ground truth
-
Analyze Judge Performance by Category - Break down alignment by different data types
-
Version Control Judge Prompts - Track prompt changes for reproducibility
If you’ve more good practices to follow, add below in comments. Would love to learn more.
But Wait, Can We Trust the Judge?
LLM judges are not perfect. They inherit biases from their own training. For example:
-
A GPT-4 judge might favor GPT-style phrasing over open-source models.
-
Judges can be “prompt-sensitive”. Small wording changes may affect verdicts.
-
They might hallucinate reasoning for why one answer is better.
Hence, follow the best practices and keep iterating to improve your judge.

The next wave of evaluation focuses on meta-judging, evaluating the evaluators themselves.
Some emerging ideas:
-
Multi-LLM consensus: Multiple judges vote or debate before giving a verdict.
-
Grounded evals: Judges verify outputs against real data or APIs.
-
Human-AI hybrid evaluation: Humans handle edge cases; LLMs handle scale.
As open-source models get stronger, expect to see judge models fine-tuned for fairness and domain expertise, like “MedJudge” for medical LLMs or “CodeJudge” for programming tasks.
📚 References & Further Reading
The LLM-as-Judge approach is not about replacing humans. It’s about accelerating truth-finding.
As models grow in complexity, human evaluation alone can’t keep up. Using LLMs as judges gives us a powerful mirror, one that helps us see how far we’ve come, and how much further we can go.
“To build better intelligence, we need better ways to measure it.”
— That’s exactly what LLM-as-Judge brings to the table.
Here’s a simple diagram showing how LLM-as-Judge fits into the AI evaluation loop:
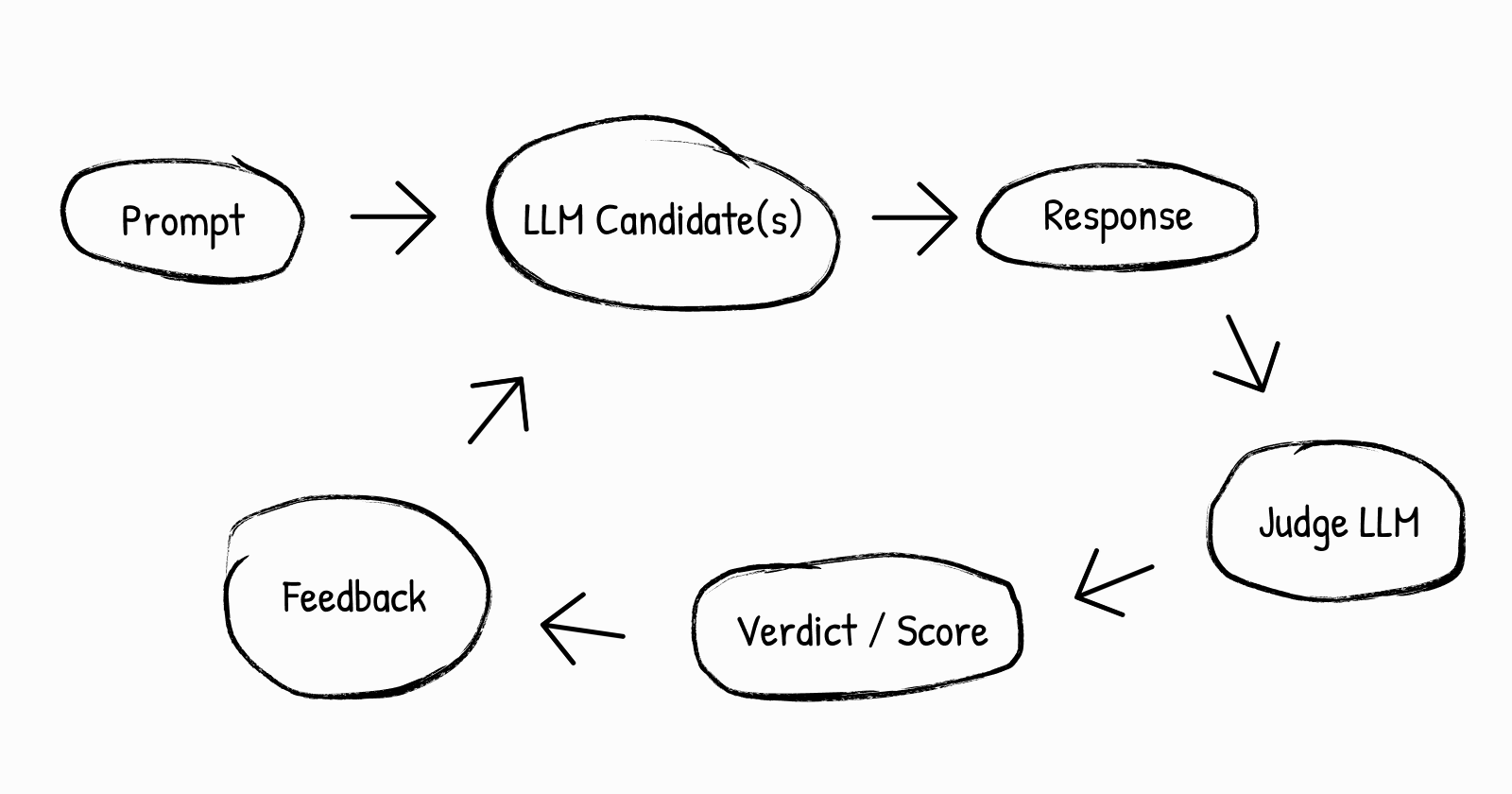
-
A user or testbench sends an input or question.
-
One or more models generate responses.
-
A judge LLM compares or evaluates these responses.
-
The verdict or score is recorded for metrics or training.
-
Feedback loops back to improve the model, thus closing the evaluation cycle.
The key to success is treating judge alignment as a first-class problem: invest time in understanding your data, clarifying evaluation criteria with domain experts, and systematically improving your judge prompts based on actual error patterns.
With an aligned judge as your foundation, you can confidently scale evaluation of RAG systems, agents, and any LLM application, knowing that improvements in metrics translate to real improvements in quality.